
L’analyse de logs au service de la qualité éditoriale
Rédigé par Rodrigue Publié le 15/03/2018
Note de Didier : Si vous ne connaissez pas encore OnCrawl, voici une courte vidéo de présentation qui résume assez bien les possibilités de leur outil. Ce que j’aime chez eux, c’est qu’ils arrivent très bien à rendre un fatras de données facile à comprendre et que leurs conseils sont très souvent directement actionnables.
L’analyse de logs est une solution performante mais parfois sous-utilisée pour optimiser son SEO. L’analyse des fichiers de logs permet de réellement comprendre comment les moteurs de recherche parcourt et se comportent sur les différentes pages d’un site web. Lors d’audits SEO, l’analyse de la qualité éditoriale fait partie intégrante du processus d’optimisation. Mais comment être sûr que Google parcourt les pages importantes d’un site, que celles-ci sont bien indexées et qu’elles aident à améliorer la fréquence de crawl ? L’analyse de logs joue un rôle majeur dans la compréhension et l’amélioration de la qualité éditoriale.
Introduction à l’analyse de logs
Un fichier de log est produit à partir d’un serveur web et contient des “hits” ou des traces de toutes les requêtes reçues par le serveur. Ces données sont stockées et comprennent des détails comme l’heure et la date à laquelle la requête a été faite, l’adresse IP de celle-ci, l’URL demandée et l’user agent du navigateur.
Pour comprendre ce qu’il se passe lorsqu’un utilisateur renseigne une URL dans un navigateur, prenons l’exemple de https://soumettre.fr. Le navigateur sépare l’URL en trois parties:
- Le protocole
- Nom du serveur
- Nom du fichier
Le nom du serveur (soumettre.fr) est converti en une adresse IP. La connexion réalisée entre le navigateur et le serveur web dédié permet d’atteindre le fichier requis. Une requête HTTP est ensuite envoyée au serveur web pour la bonne page. Chacune de ses requêtes est donc considérée comme un “hit” par le serveur web.
L’apparence d’un fichier de logs peut dépendre du type de serveur et des configurations utilisées (Apache, IIS etc..) mais il y a des attributs déjà intégrés que vous pouvez retrouver de manière quasi systématique :
- Serveur IP
- User-Agent
- Horodatage (date & heure)
- Status code HTTP
- Méthode (GET / POST)
- Requête URL (ou aussi: URL stem + URL query)
Et ensuite, d’autres attributs peuvent être ajoutés, comme :
- Nom de l’hébergeur
- Octets téléchargés
- Temps pris
- IP de requête/Client
En somme, l’analyse de fichiers de logs permet d’analyser le comportement des moteurs sur un site car chaque requête est sauvegardée. Toutefois, la compréhension et l’analyses de ses fichiers de logs peut paraître indigeste. Des outils SaaS d’analyse de logs comme OnCrawl permettent de compiler ces données sous forme de data visualisations actionnables et compréhensibles et de répondre aux questions suivantes :
- Est-ce que votre budget de crawl est dépensé de la bonne manière ?
- Quels facteurs SEO ralentissent le passage du Googlebot ?
- Quelles erreurs concernant l’accessibilité ont été rencontrées pendant le crawl ?
- Où sont les zones de carence du crawl ?
- Mes pages prioritaires sont-elles suffisamment crawlées et à quelle fréquence ?
- …
Comprendre l’impact du contenu sur le comportement de Google
Le contenu est l’un des trois critères de référencement naturel avec les liens et Rankbrain. Dans ce contexte, il est important de comprendre l’importance de la qualité éditoriale dans le processus d’indexation et de classement de Google.
Au-delà des classiques optimisations des metas title, description, du champ lexical autour de votre mot-clés ou encore des backlinks pour ne citer qu’eux ; comment être sûr que Google considère ce contenu comme pertinent pour vos lecteurs et le classera comme tel dans les résultats de recherche ? Un premier crawl de votre site web vous permettra d’accéder à un premier rapport de vos performances on-page.
Mais en croisant ces données à l’analyse de vos logs, vous pouvez mesurer l’écart entre ce que Google voit et ce qui est remonté par votre crawler. Il peut en effet y avoir des pages qui sont connues par Google mais qui ne sont pas rattachées à la structure de votre site : les pages orphelines.
Il est essentiel de comprendre l’impact de votre qualité éditoriale et des facteurs SEO liés à votre contenu sur la fréquence et le ratio de crawl de Google. Mais vous pouvez également surveiller que Google ne dépense pas inutilement du budget de crawl sur des pages inutiles et privilégie vos pages les plus importantes.
L’impact du nombre de mots sur les visites SEO
Plusieurs études ont démontré qu’un contenu riche avait de meilleures chances de se positionner dans les moteurs de recherche. Bien que l’étude ne soit pas récente, en 2012, serpIQ a étudié plus de 20 000 mots-clés. Les résultats ont montré que la longueur moyenne des 10 premiers résultats était supérieure à 2 000 mots. Le nombre moyen de mots pour le contenu à la position #1 était de 2 416. Pour la position 10, le nombre moyen de mots était de 2 032.
Nous ne pouvons cependant pas affirmer que ces données montrent qu’un grand nombre de mots produit des classements supérieurs mais qu’un grand nombre de mots est corrélé avec des classements plus élevés.
En combinant données de crawl et de logs, il est possible de comprendre l’influence du nombre de mots sur la fréquence de crawl.
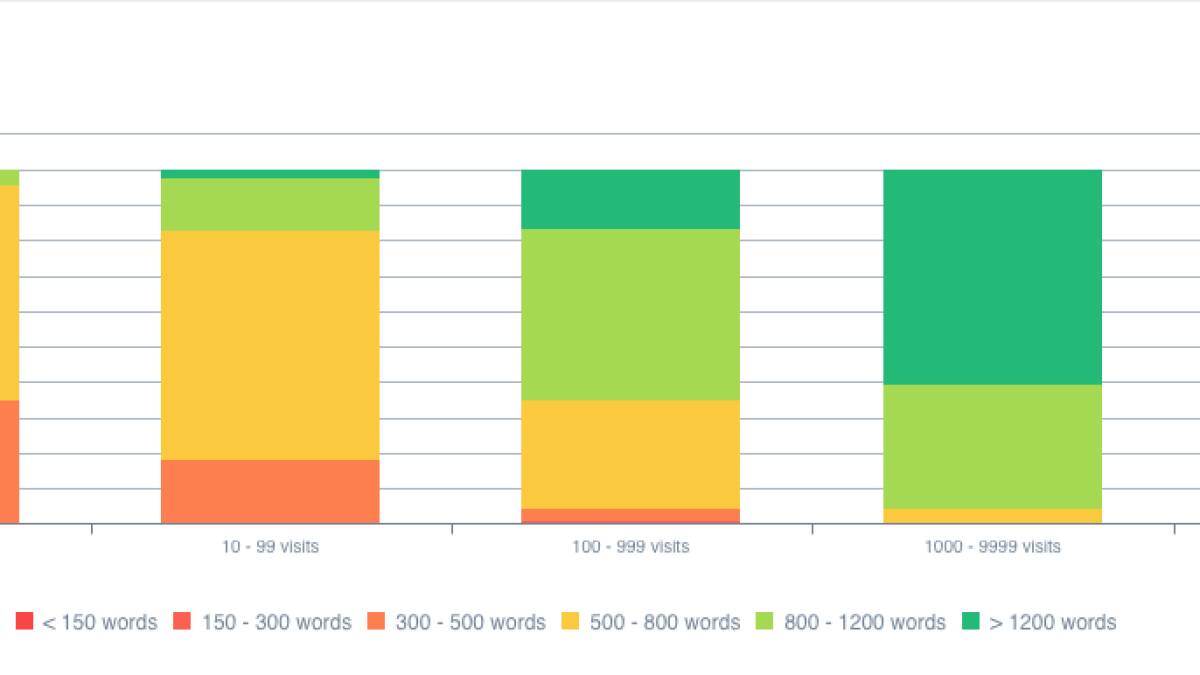
Dans le graphique ci-dessous, une très nette corrélation entre nombre de mots et visite SEO est visible. On se rend compte que des pages contenant plus de 800 mots génèrent plus de 10 000 visites depuis les résultats naturels des moteurs de recherche. A l’inverse, des contenus de moins de 500 mots se positionnent majoritairement entre 1 et 100 visites SEO. Ces données sont bien évidemment à mettre en relation avec le domaine d’activité du site en question.
Dans la représentation ci-dessous, on se rend compte une nouvelle fois de l’impact du nombre de mots sur les pages SEO actives, les pages générant donc des visites depuis les résultats organiques.
Avoir un contenu riche en mot générerait davantage de visites SEO, mais quel impact sur la fréquence de crawl ? Il semblerait que Google parcourt plus fréquemment des pages riches en contenu. Bien évidemment, la longueur n’est pas le seul facteur à prendre en compte mais également la qualité de celui-ci, sa profondeur, ses liens ou encore ses performances (temps de chargement, status codes…). Ici, on remarque que la fréquence est nettement supérieure sur des pages avec plus de 1 200 mots.
L’impact du contenu dupliqué sur la fréquence de crawl
Dans la même lignée, l’analyse du contenu dupliqué présent sur un site internet doit faire partie intégrante de tout audit SEO. Si vous avez deux pages avec des contenus identiques, comment Google va-t- il décider laquelle mettre en avant pour une même requête ? En ayant des textes similaires, vous mettez plusieurs pages en concurrence sur une même requête et prenez le risque de n’en positionner aucune. Toute les pages dupliquées ne se valent pas et une analyse minutieuse du ratio du contenu similaire contenu similaire permettra de définir les règles à intégrer : canoniques, redirections, no-index, etc.
En parallèle, il est intéressant de comprendre l’influence de ce même contenu dupliqué sur la fréquence de crawl. Dans l’exemple ci-dessous, le contenu unique ou le contenu dupliqué avec des règles de gestion des canoniques optimales possèdent une fréquence de crawl plus élevée.
En somme, la qualité du contenu a un véritable impact sur la fréquence de crawl du Googlebot et les visites SEO. D’autres facteurs sont à prendre en compte comme le nombre de lien, la profondeur de page ou la vitesse de chargement lors de vos audits éditoriaux techniques. Dans tous les cas, s’allier d’un analyseur de logs est une stratégie payante pour aller plus loin lors de vos audits SEO.
0 commentaires